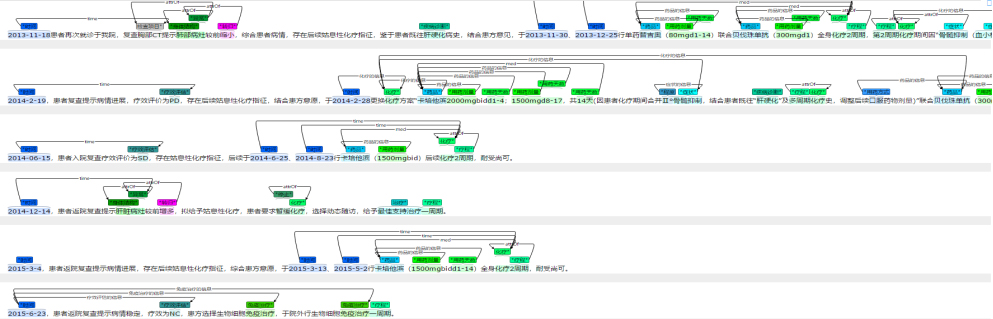
自然語言處理(lǐ)——通過文(wén)本分(fēn)割、命名(míng)實體(tǐ)識别、關系識别、句法分(fēn)析、命名(míng)實體(tǐ)識别标準化等自然語言處理(lǐ)方法,實現醫(yī)學(xué)文(wén)本的自動結構化、标準化